导语:FM是由Steffen Rendle于2010年提出的一种基于矩阵分解的机器学习模型,解决了CTR预估任务中稀疏数据的特征组合问题,在推荐和计算广告领域中得到广泛应用。本文将从背景、原理以及基于TensorFlow的代码实现三方面详细介绍FM模型。
1.FM的背景
在CTR预估的问题中存在大量的Categorical特征,我们通常的处理方法是对Categorical特征进行one-hot编码处理成0-1的二值特征,以保证不同Categorical特征之间的距离一致。形如:
可以看出,特征不同的取值个数决定了one-hot编码之后特征维度,并且其中只有1维特征是1,其余的都是0。所以one-hot编码会使得特征变得高维并且稀疏,很难进行特征组合得到高阶的交叉特征。那为什么要进行特征组合呢?实际上,大量的特征之间存在潜在的关联。举个简单例子,女性用户倾向于点击化妆品、服装类型的物品,而男性用户则倾向于点击运动、电子类的物品,所以相比一阶特征,性别交叉物品种类的二阶特征会对CTR预估有更重要的作用。
2.FM的原理
一般的线性模型 没有考虑特征组合,FM模型在线性模型的基础上增加二阶交叉特征,模型如下: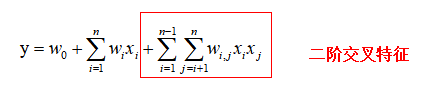
然而针对大规模的稀疏数据,这样的模型还存在一些问题。从模型的表达式可以看出,$x_i\cdot x_j$是两个不同特征向量的内积,只有当$x_i$和$x_j$都不为0时内积才有意义,所以大量的稀疏数据会导致模型计算复杂度过高,很难训练得到$w_{i,j}$。
为了得到$w_{i,j}$,FM利用矩阵分解的思想,将交叉项系数矩阵W分解成两个低秩矩阵:$W=VV^T$
$w_{i,j} = v_i v_{j}`{T}$,所以二阶交叉特征部分变形为: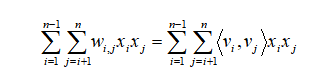
由于必须将$x_i\cdot x_j$分开才能有效地利用稀疏数据,所以FM对表达式做了进一步的化简: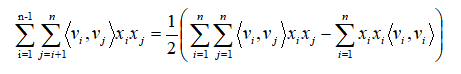
这步化简如何来的呢?其实不难发现等式的左边就是n*n阶对称矩阵的上三角部分,它的面积恰好等于矩形减掉对角线之后的一半。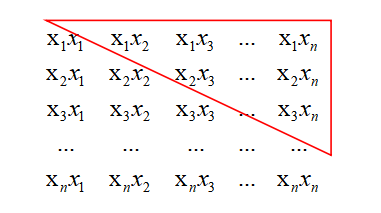
由于$\left< v_i,v_j \right>$等于$\sum_{f=1}^{k}v_{i,f}v_{j,f}$,所以展开后公式为: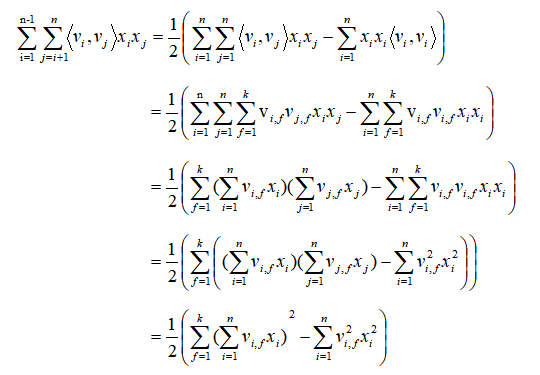
FM的表达式经过变形之后,所有包含非零$x_i$的组合样本都可以用来学习$v_i$,这在很大程度上避免了数据稀疏造成参数估计不准确的影响。
用梯度下降法进行模型训练时需要求预测值y_对各个参数的偏导数: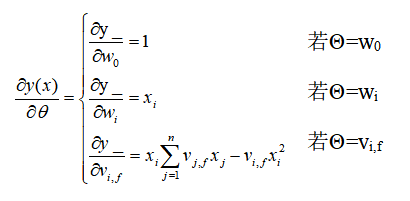
模型的参数从$\frac{n(n-1)}{2}$减少为nk+n+1,模型的计算复杂度从$O \left( n^{2} \right)$降低到$O \left( nk \right)$,综上FM是一个针对大规模稀疏数据的高效预测模型。
3.基于TensorFlow的FM实现
|
|